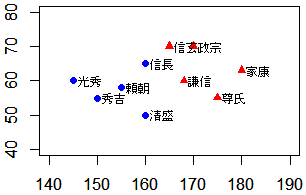
|
→ 携帯用は別頁
≪散布図の作り方≫
◇この教材は,高校生が表計算ソフトを使って,数学Ⅰの「データ分析」レベルの内容を扱うときの「演習の手引き」として書いたものです.(筆者自身用の備忘録でもある)
◇●1~●4のソフトについて操作方法を解説していますが,全部読む必要はありません.自分のパソコンで使えるソフトを選んで,読んでください.
【要約】 《筆者の実験結果です.異論はあり得ます》
●1「Microsoft Excel 2021」(インストール型) ●2 無料で使える「Excel for the web」 ●3 無料で使える「Google スプレッドシート」 ●4 無料でインストールできる統計用ソフト「R」
◎印:できる,〇:概ねできる,▼:薦めない
1. 散布図
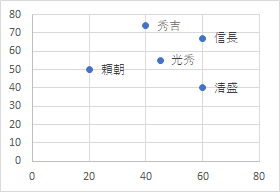
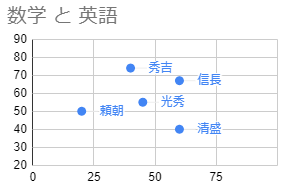
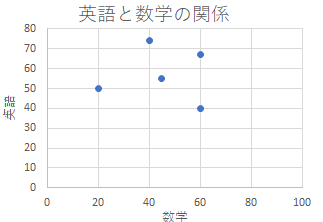 -図1- 何人かの生徒の「数学の得点」と「英語の得点」を調べたら,表1の結果が得られたとする.(架空データ) これら2種類の得点には,どのような関係があるかを調べるには,相関係数,平均,標準偏差のような数値を利用する方法の他に,図1のように2種類のデータをx,y座標とする点で表して,直接目で観察する方法がある.図1は散布図と呼ばれる. ●1 「Microsoft Excel 2021」(インストール型)
◎:できる
(1) 表1のデータがExcel上にあるとして,列タイトル(数学,英語)を含めて,桃色で示した2列のデータ範囲をドラッグして反転表示にする.(この段階では,まだ名前の列を含めない)
(2) 挿入→散布図 ここまでの作業で,図1のようなグラフができる.(グラフのタイトル,縦横軸のラベルは直接書き込める) ●2 無料で使える「Excel for the web」
⇒導入方法は前のページ◎:できる
作業手順は,●1とほぼ同じ. |
●3 無料で使える「Google スプレッドシート」
⇒導入方法は前のページ◎:できる 作業手順は,●1,●2とほぼ同じ (1) 表1のデータがスプレッドシート上にあるとして,列タイトル(数学,英語)を含めて,桃色で示した2列のデータ範囲をドラッグして反転表示にする.(この段階では,まだ名前の列を含めない) (2) 挿入→グラフで,一旦,円グラフが表示されるので,グラフの種類を散布図に選び直す. ●4 無料でインストールできる統計用ソフト「R」
⇒導入方法は前のページ◎:できる
• Rのコマンドプロンプトから,次のように入力する. • Rでは変数名(ここではベクトル名:数字の束をベクトルという)に日本語漢字も使えるが,日本語漢字の変数を使うと,プロンルトでの画面上の位置が微妙にずれるので,半角英数字の方が使いやすい.代入する記号は,山かっこ(<)とハイフン(−)を組み合わせたもの,cは数字の束(ベクトル)を表すときに使う. 各行末でエンターキーを押す.plot()が散布図を表示する関数.
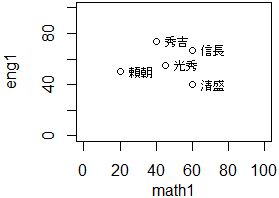
math1<-c(60,20,45,60,40)
により,散布図が表示されるが,x範囲,y範囲に全く無駄がないのでやや窮屈な図になる.x範囲,y範囲を指定するには,次のようにxlim=c(x1,x2)などの形で,(start,end)のベクトルで示す.x1,x2の大小が逆の場合は,横軸が反転表示される.
eng1<-c(40,50,55,67,74) plot(math1,eng1) 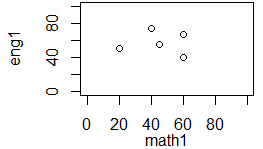 -図2-
plot(math1,eng1,xlim=c(0,100),ylim=c(0,100))
• 1つの○が1人分のデータで,そのx座標が数学の得点,y座標が英語の得点を表す.• マーカーは,既定値が○(pch=1)で,pch=番号の形で指定できる.
plot(math1,eng1,xlim=c(0,100),ylim=c(0,100), pch=15,col=c('red','blue','green','#990000'))
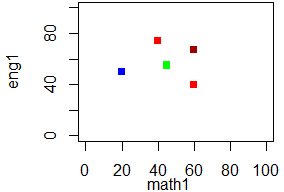 -図3- |